几个概念
NameNode被格式化之后,将在/opt/module/hadoop-3.1.3/data/tmp/dfs/name/current目录中产生如下文件:
fsimage_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
在实验中h102看到的是:
-rw-rw-r--. 1 zyi zyi 42 Jun 30 02:59 edits_0000000000000001543-0000000000000001544
-rw-rw-r--. 1 zyi zyi 42 Jun 30 03:59 edits_0000000000000001545-0000000000000001546
-rw-rw-r--. 1 zyi zyi 1048576 Jun 30 03:59 edits_inprogress_0000000000000001547
-rw-rw-r--. 1 zyi zyi 1407 Jun 30 02:59 fsimage_0000000000000001544
-rw-rw-r--. 1 zyi zyi 62 Jun 30 02:59 fsimage_0000000000000001544.md5
-rw-rw-r--. 1 zyi zyi 1407 Jun 30 03:59 fsimage_0000000000000001546
-rw-rw-r--. 1 zyi zyi 62 Jun 30 03:59 fsimage_0000000000000001546.md5
-rw-rw-r--. 1 zyi zyi 5 Jun 30 03:59 seen_txid
-rw-rw-r--. 1 zyi zyi 218 Jun 11 07:05 VERSION
Fsimage文件
该文件是HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息。
hdfs oiv
我们查看hdfs oiv命令的帮助:
[root@h102 current]# hdfs oiv -h
Usage: bin/hdfs oiv [OPTIONS] -i INPUTFILE -o OUTPUTFILE
Offline Image Viewer
View a Hadoop fsimage INPUTFILE using the specified PROCESSOR,
saving the results in OUTPUTFILE.
The oiv utility will attempt to parse correctly formed image files
and will abort fail with mal-formed image files.
The tool works offline and does not require a running cluster in
order to process an image file.
The following image processors are available:
* XML: This processor creates an XML document with all elements of
the fsimage enumerated, suitable for further analysis by XML
tools.
* ReverseXML: This processor takes an XML file and creates a
binary fsimage containing the same elements.
* FileDistribution: This processor analyzes the file size
distribution in the image.
-maxSize specifies the range [0, maxSize] of file sizes to be
analyzed (128GB by default).
-step defines the granularity of the distribution. (2MB by default)
-format formats the output result in a human-readable fashion
rather than a number of bytes. (false by default)
* Web: Run a viewer to expose read-only WebHDFS API.
-addr specifies the address to listen. (localhost:5978 by default)
It does not support secure mode nor HTTPS.
* Delimited (experimental): Generate a text file with all of the elements common
to both inodes and inodes-under-construction, separated by a
delimiter. The default delimiter is \t, though this may be
changed via the -delimiter argument.
Required command line arguments:
-i,--inputFile <arg> FSImage or XML file to process.
Optional command line arguments:
-o,--outputFile <arg> Name of output file. If the specified
file exists, it will be overwritten.
(output to stdout by default)
If the input file was an XML file, we
will also create an <outputFile>.md5 file.
-p,--processor <arg> Select which type of processor to apply
against image file. (XML|FileDistribution|
ReverseXML|Web|Delimited)
The default is Web.
-delimiter <arg> Delimiting string to use with Delimited processor.
-t,--temp <arg> Use temporary dir to cache intermediate result to generate
Delimited outputs. If not set, Delimited processor constructs
the namespace in memory before outputting text.
-h,--help Display usage information and exit
以上可以看到这条命令的作用 Offline Image Viewer View a Hadoop fsimage INPUTFILE using the specified PROCESSOR, saving the results in OUTPUTFILE. 最常用的语法: hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径
[root@h102 current]# hdfs oiv -p XML -i fsimage_0000000000000001586 -o /opt/software/fsimage-1.xml
2021-07-01 00:32:35,781 INFO offlineImageViewer.FSImageHandler: Loading 3 strings
查看fsimagfe-1.xml:
<?xml version="1.0"?>
-<fsimage>
-<version>
<layoutVersion>-64</layoutVersion>
<onDiskVersion>1</onDiskVersion>
<oivRevision>ba631c436b806728f8ec2f54ab1e289526c90579</oivRevision>
</version>
-<NameSection>
<namespaceId>632455869</namespaceId>
<genstampV1>1000</genstampV1>
<genstampV2>1045</genstampV2>
<genstampV1Limit>0</genstampV1Limit>
<lastAllocatedBlockId>1073741864</lastAllocatedBlockId>
<txid>1586</txid>
</NameSection>
-<ErasureCodingSection>
-<erasureCodingPolicy>
<policyId>1</policyId>
<policyName>RS-6-3-1024k</policyName>
<cellSize>1048576</cellSize>
<policyState>DISABLED</policyState>
-<ecSchema>
<codecName>rs</codecName>
<dataUnits>6</dataUnits>
<parityUnits>3</parityUnits>
</ecSchema>
</erasureCodingPolicy>
-<erasureCodingPolicy>
<policyId>2</policyId>
<policyName>RS-3-2-1024k</policyName>
<cellSize>1048576</cellSize>
<policyState>DISABLED</policyState>
-<ecSchema>
<codecName>rs</codecName>
<dataUnits>3</dataUnits>
<parityUnits>2</parityUnits>
</ecSchema>
</erasureCodingPolicy>
-<erasureCodingPolicy>
<policyId>3</policyId>
<policyName>RS-LEGACY-6-3-1024k</policyName>
<cellSize>1048576</cellSize>
<policyState>DISABLED</policyState>
-<ecSchema>
<codecName>rs-legacy</codecName>
<dataUnits>6</dataUnits>
<parityUnits>3</parityUnits>
</ecSchema>
</erasureCodingPolicy>
-<erasureCodingPolicy>
<policyId>4</policyId>
<policyName>XOR-2-1-1024k</policyName>
<cellSize>1048576</cellSize>
<policyState>DISABLED</policyState>
-<ecSchema>
<codecName>xor</codecName>
<dataUnits>2</dataUnits>
<parityUnits>1</parityUnits>
</ecSchema>
</erasureCodingPolicy>
-<erasureCodingPolicy>
<policyId>5</policyId>
<policyName>RS-10-4-1024k</policyName>
<cellSize>1048576</cellSize>
<policyState>DISABLED</policyState>
-<ecSchema>
<codecName>rs</codecName>
<dataUnits>10</dataUnits>
<parityUnits>4</parityUnits>
</ecSchema>
</erasureCodingPolicy>
</ErasureCodingSection>
-<INodeSection>
<lastInodeId>16480</lastInodeId>
<numInodes>16</numInodes>
-<inode>
<id>16385</id>
<type>DIRECTORY</type>
<name/>
<mtime>1623409999622</mtime>
<permission>zyi:supergroup:0755</permission>
<nsquota>9223372036854775807</nsquota>
<dsquota>-1</dsquota>
</inode>
-<inode>
<id>16386</id>
<type>DIRECTORY</type>
<name>input</name>
<mtime>1622690609129</mtime>
<permission>zyi:supergroup:0755</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
-<inode>
<id>16387</id>
<type>FILE</type>
<name>word.txt</name>
<replication>3</replication>
<mtime>1622687321202</mtime>
<atime>1622727500321</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>zyi:supergroup:0644</permission>
-<blocks>
-<block>
<id>1073741825</id>
<genstamp>1001</genstamp>
<numBytes>1248</numBytes>
</block>
</blocks>
<storagePolicyId>0</storagePolicyId>
</inode>
-<inode>
<id>16454</id>
<type>DIRECTORY</type>
<name>output</name>
<mtime>1622706392626</mtime>
<permission>zyi:supergroup:0755</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
-<inode>
<id>16460</id>
<type>FILE</type>
<name>part-r-00000</name>
<replication>3</replication>
<mtime>1622706392348</mtime>
<atime>1622706392055</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>zyi:supergroup:0644</permission>
-<blocks>
-<block>
<id>1073741854</id>
<genstamp>1030</genstamp>
<numBytes>1013</numBytes>
</block>
</blocks>
<storagePolicyId>0</storagePolicyId>
</inode>
-<inode>
<id>16462</id>
<type>FILE</type>
<name>_SUCCESS</name>
<replication>3</replication>
<mtime>1622706392636</mtime>
<atime>1622706392626</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>zyi:supergroup:0644</permission>
<storagePolicyId>0</storagePolicyId>
</inode>
-<inode>
<id>16469</id>
<type>DIRECTORY</type>
<name>tmp</name>
<mtime>1623157585734</mtime>
<permission>zyi:supergroup:0770</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
-<inode>
<id>16470</id>
<type>DIRECTORY</type>
<name>hadoop-yarn</name>
<mtime>1623157585735</mtime>
<permission>zyi:supergroup:0770</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
-<inode>
<id>16471</id>
<type>DIRECTORY</type>
<name>staging</name>
<mtime>1623157585735</mtime>
<permission>zyi:supergroup:0770</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
-<inode>
<id>16472</id>
<type>DIRECTORY</type>
<name>history</name>
<mtime>1623157585912</mtime>
<permission>zyi:supergroup:0770</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
-<inode>
<id>16473</id>
<type>DIRECTORY</type>
<name>done</name>
<mtime>1623157585735</mtime>
<permission>zyi:supergroup:0770</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
-<inode>
<id>16474</id>
<type>DIRECTORY</type>
<name>done_intermediate</name>
<mtime>1623157585912</mtime>
<permission>zyi:supergroup:1777</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
-<inode>
<id>16475</id>
<type>DIRECTORY</type>
<name>sanguo</name>
<mtime>1623410691838</mtime>
<permission>zyi:supergroup:0755</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
-<inode>
<id>16477</id>
<type>FILE</type>
<name>weiguo.txt</name>
<replication>3</replication>
<mtime>1623410347504</mtime>
<atime>1623410346845</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>zyi:supergroup:0644</permission>
-<blocks>
-<block>
<id>1073741861</id>
<genstamp>1037</genstamp>
<numBytes>7</numBytes>
</block>
</blocks>
<storagePolicyId>0</storagePolicyId>
</inode>
-<inode>
<id>16478</id>
<type>FILE</type>
<name>wuguo.txt</name>
<replication>3</replication>
<mtime>1623410414600</mtime>
<atime>1623410414147</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>zyi:supergroup:0644</permission>
-<blocks>
-<block>
<id>1073741862</id>
<genstamp>1038</genstamp>
<numBytes>6</numBytes>
</block>
</blocks>
<storagePolicyId>0</storagePolicyId>
</inode>
-<inode>
<id>16480</id>
<type>FILE</type>
<name>shuguo.txt</name>
<replication>3</replication>
<mtime>1623411476257</mtime>
<atime>1623410691378</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>zyi:supergroup:0644</permission>
-<blocks>
-<block>
<id>1073741864</id>
<genstamp>1045</genstamp>
<numBytes>14</numBytes>
</block>
</blocks>
<storagePolicyId>0</storagePolicyId>
</inode>
</INodeSection>
<INodeReferenceSection/>
-<SnapshotSection>
<snapshotCounter>0</snapshotCounter>
<numSnapshots>0</numSnapshots>
</SnapshotSection>
-<INodeDirectorySection>
-<directory>
<parent>16385</parent>
<child>16386</child>
<child>16454</child>
<child>16475</child>
<child>16469</child>
</directory>
-<directory>
<parent>16386</parent>
<child>16387</child>
</directory>
-<directory>
<parent>16454</parent>
<child>16462</child>
<child>16460</child>
</directory>
-<directory>
<parent>16469</parent>
<child>16470</child>
</directory>
-<directory>
<parent>16470</parent>
<child>16471</child>
</directory>
-<directory>
<parent>16471</parent>
<child>16472</child>
</directory>
-<directory>
<parent>16472</parent>
<child>16473</child>
<child>16474</child>
</directory>
-<directory>
<parent>16475</parent>
<child>16480</child>
<child>16477</child>
<child>16478</child>
</directory>
</INodeDirectorySection>
<FileUnderConstructionSection/>
-<SecretManagerSection>
<currentId>0</currentId>
<tokenSequenceNumber>0</tokenSequenceNumber>
<numDelegationKeys>0</numDelegationKeys>
<numTokens>0</numTokens>
</SecretManagerSection>
-<CacheManagerSection>
<nextDirectiveId>1</nextDirectiveId>
<numDirectives>0</numDirectives>
<numPools>0</numPools>
</CacheManagerSection>
</fsimage>
存储内容的名称在此表现:

 可以看到input和output的文件夹,文件word.txt是/input目录下的文件。
input的ID:16386
可以看到input和output的文件夹,文件word.txt是/input目录下的文件。
input的ID:16386
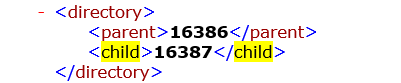 文件中表示是一个父节点,下面有一个子节点16387
文件中表示是一个父节点,下面有一个子节点16387
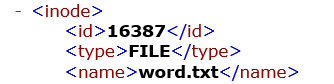 就是文件word.txt,层次很清楚的树形结构。
就是文件word.txt,层次很清楚的树形结构。
注意:Fsimage 中没有记录块所对应 DataNode
Edits文件
它是存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
hdfs oev
查看hdfs oev命令的帮助:
[root@h102 current]# hdfs oev -h
Usage: bin/hdfs oev [OPTIONS] -i INPUT_FILE -o OUTPUT_FILE
Offline edits viewer
**Parse a Hadoop edits log file INPUT_FILE and save results
in OUTPUT_FILE.**
Required command line arguments:
-i,--inputFile <arg> edits file to process, xml (case
insensitive) extension means XML format,
any other filename means binary format.
XML/Binary format input file is not allowed
to be processed by the same type processor.
-o,--outputFile <arg> Name of output file. If the specified
file exists, it will be overwritten,
format of the file is determined
by -p option
Optional command line arguments:
-p,--processor <arg> Select which type of processor to apply
against image file, currently supported
processors are: binary (native binary format
that Hadoop uses), xml (default, XML
format), stats (prints statistics about
edits file)
-h,--help Display usage information and exit
-f,--fix-txids Renumber the transaction IDs in the input,
so that there are no gaps or invalid
transaction IDs.
-r,--recover When reading binary edit logs, use recovery
mode. This will give you the chance to skip
corrupt parts of the edit log.
-v,--verbose More verbose output, prints the input and
output filenames, for processors that write
to a file, also output to screen. On large
image files this will dramatically increase
processing time (default is false).
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
查看前现在/目录下建立了一个目录:newone,并上传文件lic.txt
[root@h102 current]# hdfs oev -p XML -i edits_inprogress_0000000000000001595 -o /opt/software/edits-1.xml
[root@h102 current]# ll /opt/software/
total 520616
-rw-r--r--. 1 root root 2745 Jul 1 04:26 edits-1.xml
-rw-r--r--. 1 root root 7237 Jul 1 00:35 fsimage-1.xml
在浏览器上打开edits-1.xml
<?xml version="1.0" encoding="UTF-8" standalone="true"?>
-<EDITS>
<EDITS_VERSION>-64</EDITS_VERSION>
-<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
-<DATA>
<TXID>1595</TXID>
</DATA>
</RECORD>
-<RECORD>
<OPCODE>OP_MKDIR</OPCODE>
-<DATA>
<TXID>1596</TXID>
<LENGTH>0</LENGTH>
<INODEID>16481</INODEID>
<PATH>/newone</PATH>
<TIMESTAMP>1625127931249</TIMESTAMP>
-<PERMISSION_STATUS>
<USERNAME>zyi</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>493</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
+<RECORD>
-<RECORD>
<OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE>
-<DATA>
<TXID>1598</TXID>
<BLOCK_ID>1073741865</BLOCK_ID>
</DATA>
</RECORD>
-<RECORD>
<OPCODE>OP_SET_GENSTAMP_V2</OPCODE>
-<DATA>
<TXID>1599</TXID>
<GENSTAMPV2>1046</GENSTAMPV2>
</DATA>
</RECORD>
-<RECORD>
<OPCODE>OP_ADD_BLOCK</OPCODE>
-<DATA>
<TXID>1600</TXID>
<PATH>/newone/lic.txt</PATH>
-<BLOCK>
<BLOCK_ID>1073741865</BLOCK_ID>
<NUM_BYTES>0</NUM_BYTES>
<GENSTAMP>1046</GENSTAMP>
</BLOCK>
<RPC_CLIENTID/>
<RPC_CALLID>-2</RPC_CALLID>
</DATA>
</RECORD>
-<RECORD>
<OPCODE>OP_CLOSE</OPCODE>
-<DATA>
<TXID>1601</TXID>
<LENGTH>0</LENGTH>
<INODEID>0</INODEID>
<PATH>/newone/lic.txt</PATH>
<REPLICATION>3</REPLICATION>
<MTIME>1625127944362</MTIME>
<ATIME>1625127944012</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME/>
<CLIENT_MACHINE/>
<OVERWRITE>false</OVERWRITE>
-<BLOCK>
<BLOCK_ID>1073741865</BLOCK_ID>
<NUM_BYTES>304</NUM_BYTES>
<GENSTAMP>1046</GENSTAMP>
</BLOCK>
-<PERMISSION_STATUS>
<USERNAME>zyi</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>420</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
</EDITS>
里面记录了操作:建目录
 上传文件:
上传文件:

seen_txid文件
该文件保存的是一个数字,就是最后一个edits_的数字,如我们在实验中的这个seen_txid
[root@h102 current]# cat seen_txid
1547
VERSION
该文件记录了集群信息,namenode和datanode需要保持一致。
[root@h102 current]# cat VERSION
#Fri Jun 11 07:05:22 EDT 2021
namespaceID=632455869
clusterID=CID-fd675fc9-998e-44d4-84f9-baa472f33d21
cTime=1622624666933
storageType=NAME_NODE
blockpoolID=BP-1568640629-192.168.110.82-1622624666933
layoutVersion=-64
HDFS文件修改
NameNode的操作
磁盘中备份元数据的 FsImage,引入 Edits 文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到 Edits 中。只记录改变的操作。实际修改的数据在内存。 每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。 即:服务器启动,读FsImage+Edits;而服务器关机,合并FsImage+Edits
SecondaryNamenode的操作
如果长时间添加数据到 Edits 中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行 FsImage 和 Edits 的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于 FsImage 和 Edits 的合并。
NN与2NN协同

第一阶段:NameNode 启动
(1)第一次启动 NameNode 格式化后,创建 Fsimage 和 Edits 文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode 记录操作日志,更新滚动日志。
(4)NameNode 在内存中对元数据进行增删改。
第二阶段:Secondary NameNode 工作
(1)Secondary NameNode 询问 NameNode 是否需要 CheckPoint。直接带回 NameNode是否检查结果。
(2)Secondary NameNode 请求执行 CheckPoint。
(3)NameNode 滚动正在写的 Edits 日志。
(4)将滚动前的编辑日志和镜像文件拷贝到 Secondary NameNode。
(5)Secondary NameNode 加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件 fsimage.chkpoint。
(7)拷贝 fsimage.chkpoint 到 NameNode。
(8)NameNode 将 fsimage.chkpoint 重新命名成 fsimage。
Check point时间一般一个小时,Edits条目一百万条。
 上图可以看到每一个小时合并一次,下次合并将大于1594的内容。
上图可以看到每一个小时合并一次,下次合并将大于1594的内容。
在实验中可以查看NN和2NN的数据不同:
[root@h102 current]# pwd
/opt/module/hadoop-3.1.3/data/dfs/name/current
[root@h102 current]# ll
total 11604
-rw-rw-r--. 1 zyi zyi 42 Jun 2 05:12 edits_0000000000000000001-0000000000000000002
-rw-rw-r--. 1 zyi zyi 42 Jun 2 06:12 edits_0000000000000000003-0000000000000000004
......
-rw-rw-r--. 1 zyi zyi 42 Jun 30 02:59 edits_0000000000000001543-0000000000000001544
-rw-rw-r--. 1 zyi zyi 42 Jun 30 03:59 edits_0000000000000001545-0000000000000001546
-rw-rw-r--. 1 zyi zyi 1048576 Jun 30 03:59 edits_inprogress_0000000000000001547
-rw-rw-r--. 1 zyi zyi 1407 Jun 30 02:59 fsimage_0000000000000001544
-rw-rw-r--. 1 zyi zyi 62 Jun 30 02:59 fsimage_0000000000000001544.md5
-rw-rw-r--. 1 zyi zyi 1407 Jun 30 03:59 fsimage_0000000000000001546
-rw-rw-r--. 1 zyi zyi 62 Jun 30 03:59 fsimage_0000000000000001546.md5
-rw-rw-r--. 1 zyi zyi 5 Jun 30 03:59 seen_txid
-rw-rw-r--. 1 zyi zyi 218 Jun 11 07:05 VERSION
[root@h104 current]# pwd
/opt/module/hadoop-3.1.3/data/dfs/namesecondary/current
[root@h104 current]# ll
total 8052
-rw-rw-r--. 1 zyi zyi 42 Jun 2 05:12 edits_0000000000000000001-0000000000000000002
-rw-rw-r--. 1 zyi zyi 42 Jun 2 06:12 edits_0000000000000000003-0000000000000000004
......
-rw-rw-r--. 1 zyi zyi 42 Jun 25 04:52 edits_0000000000000001307-0000000000000001308
-rw-rw-r--. 1 zyi zyi 1407 Jun 25 03:52 fsimage_0000000000000001306
-rw-rw-r--. 1 zyi zyi 62 Jun 25 03:52 fsimage_0000000000000001306.md5
-rw-rw-r--. 1 zyi zyi 1407 Jun 25 04:52 fsimage_0000000000000001308
-rw-rw-r--. 1 zyi zyi 62 Jun 25 04:52 fsimage_0000000000000001308.md5
-rw-rw-r--. 1 zyi zyi 218 Jun 25 04:52 VERSION