概述
单机/单主的性能瓶颈
- IOPS 约100k/s读,20-80k/s写
- 单机内存限制
Cluster
- 访问,负载均衡
- 内存,扩展
- 灾难恢复
集群存储空间设计
设计原理
Redis cluster 采用虚拟哈希槽分区,所有的键根据哈希函数映射到 0 ~ 16383 整数槽内,每个key通过crc16校验后对16384取模来决定放置哪个槽(slot),每一个节点负责维护一部分槽以及槽所映射的键值数据。
计算公式:slot = crc16(key) % 16383。

这种结构很容易添加或者删除节点,并且无论是添加删除或者修改某一个节点,都不会造成集群不可用的状态。 当需要增加节点时,把其他节点的某些哈希槽挪到新节点; 当需要移除节点时,把移除节点上的哈希槽挪到其他节点。
参考文档:http://www.zzvips.com/article/205769.html
为什么设计成16384(2^14)个槽位,作者给出了解释 https://github.com/antirez/redis/issues/2576
1.如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大。
如上所述,在消息头中,最占空间的是myslots[cluster_slots/8]。 当槽位为65536时,这块的大小是:65536÷8÷1024=8kb因为每秒钟,redis节点需要发送一定数量的ping消息作为心跳包,如果槽位为65536,这个ping消息的消息头太大了,浪费带宽。
2.redis的集群主节点数量基本不可能超过1000个。 如上所述,集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者,不建议redis cluster节点数量超过1000个。 那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。
3.槽位越小,节点少的情况下,压缩率高 redis主节点的配置信息中,它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中,会对bitmap进行压缩,但是如果bitmap的填充率slots / n很高的话(n表示节点数),bitmap的压缩率就很低。 如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。 而16384÷8÷1024=2kb
综上所述,作者决定取16384个槽。
集群内部通信
- 每个节点相互通信,保存各自库中槽的编号数据
- 一次命中,直接返回
- 一次未命中,告知具体位置
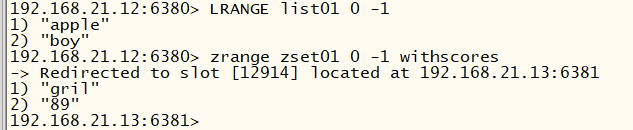
如上图
- 在192.168.21.12:6380查询list01时,一次命中
- 查询zset01时,未命中,告知并跳转到192.168.21.13:6381,返回结果
Lab实验
环境设置
初始化
| Cluster Role | IP addr | Port |
|---|---|---|
| Group 1:Master | 192.168.21.11 | 6379 |
| Group 1:Slave | 192.168.21.11 | 6382 |
| Group 2:Master | 192.168.21.12 | 6380 |
| Group 2:Slave | 192.168.21.12 | 6383 |
| Group 3:Master | 192.168.21.13 | 6381 |
| Group 3:Slave | 192.168.21.13 | 6384 |

配置命令
port 6380 daemonize no bind 0.0.0.0 dir “/root/redis-6.0.6/data” protected-mode no cluster-enabled yescluster-config-file node-6380.confcluster-node-timeout 10000
启动集群
- 6 Server按conf启动
- 命令启动
[root@worker-01 conf]# ../src/redis-cli –cluster create 192.168.21.11:6379 192.168.21.12:6380 192.168.21.13:6381 192.168.21.12:6383 192.168.21.13:6384 192.168.21.11:6382 –cluster-replicas 1
- 最后的参数 1 表示集群中master的slave数为1
- 按照列出的server前后顺序分配master和slave
Performing hash slots allocation on 6 nodes… Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 192.168.21.12:6383 to 192.168.21.11:6379 Adding replica 192.168.21.13:6384 to 192.168.21.12:6380 Adding replica 192.168.21.11:6382 to 192.168.21.13:6381 M: b9b0603f8995f275576f4e9ad2b98708b13ba40e 192.168.21.11:6379 slots:[0-5460] (5461 slots) master M: e0379031bbe11a1ad523910d9a3d72618331e930 192.168.21.12:6380 slots:[5461-10922] (5462 slots) master M: 01215826194d3b2fc182b32465d443a85ad11143 192.168.21.13:6381 slots:[10923-16383] (5461 slots) master S: ccd38a4b40a50048b969bba946bbf1cc16f21a96 192.168.21.12:6383 replicates b9b0603f8995f275576f4e9ad2b98708b13ba40e S: d5c0f25036222406817bc9bac9bab4f30cdfa86b 192.168.21.13:6384 replicates e0379031bbe11a1ad523910d9a3d72618331e930 S: f21a44755356bbaa416f4ee61092f4bb7052ef69 192.168.21.11:6382 replicates 01215826194d3b2fc182b32465d443a85ad11143
Can I set the above configuration? (type ‘yes’ to accept): yes
Nodes configuration updated Assign a different config epoch to each node Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join .
Performing Cluster Check (using node 192.168.21.11:6379) M: b9b0603f8995f275576f4e9ad2b98708b13ba40e 192.168.21.11:6379 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: 01215826194d3b2fc182b32465d443a85ad11143 192.168.21.13:6381 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: f21a44755356bbaa416f4ee61092f4bb7052ef69 192.168.21.11:6382 slots: (0 slots) slave replicates 01215826194d3b2fc182b32465d443a85ad11143 S: ccd38a4b40a50048b969bba946bbf1cc16f21a96 192.168.21.12:6383 slots: (0 slots) slave replicates b9b0603f8995f275576f4e9ad2b98708b13ba40e M: e0379031bbe11a1ad523910d9a3d72618331e930 192.168.21.12:6380 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: d5c0f25036222406817bc9bac9bab4f30cdfa86b 192.168.21.13:6384 slots: (0 slots) slave replicates e0379031bbe11a1ad523910d9a3d72618331e930 All nodes agree about slots configuration.
Check for open slots… Check slots coverage… All 16384 slots covered.
系统自动将Cluster配置好。 同时,定义好的系统文件被更改,记录下系统配置情况:

- 查看一组master/slave的log: Master-6379:

Slave-6383:

模拟灾难恢复
停止Master-6380

查看Slave,timeout=10s
10s内找Master同步,过了timeout时间,系统failover机制作用将6384变成Master

- 其他server的配置发生改变
Master-6380已经标记为fail,6384变为Master

- 重新启动6380
发现其连接到Master-6384,成为Slave

在配置文件上也反映了这一现象

6384上的log记录了这一过程

其他server同步记录下

在redis-cli模式下也可以通过命令查看最终节点情况

- 最终结果
