整体结构
Microsoft SQL Server 服务由一个实例(Instance)和多个数据库(Databases)组成,
实例包含了后台线程和占用的内存,数据库在存在于存储上的文件。默认的系统数据库包括 master、model、msdb、Resource 以及 tempdb。
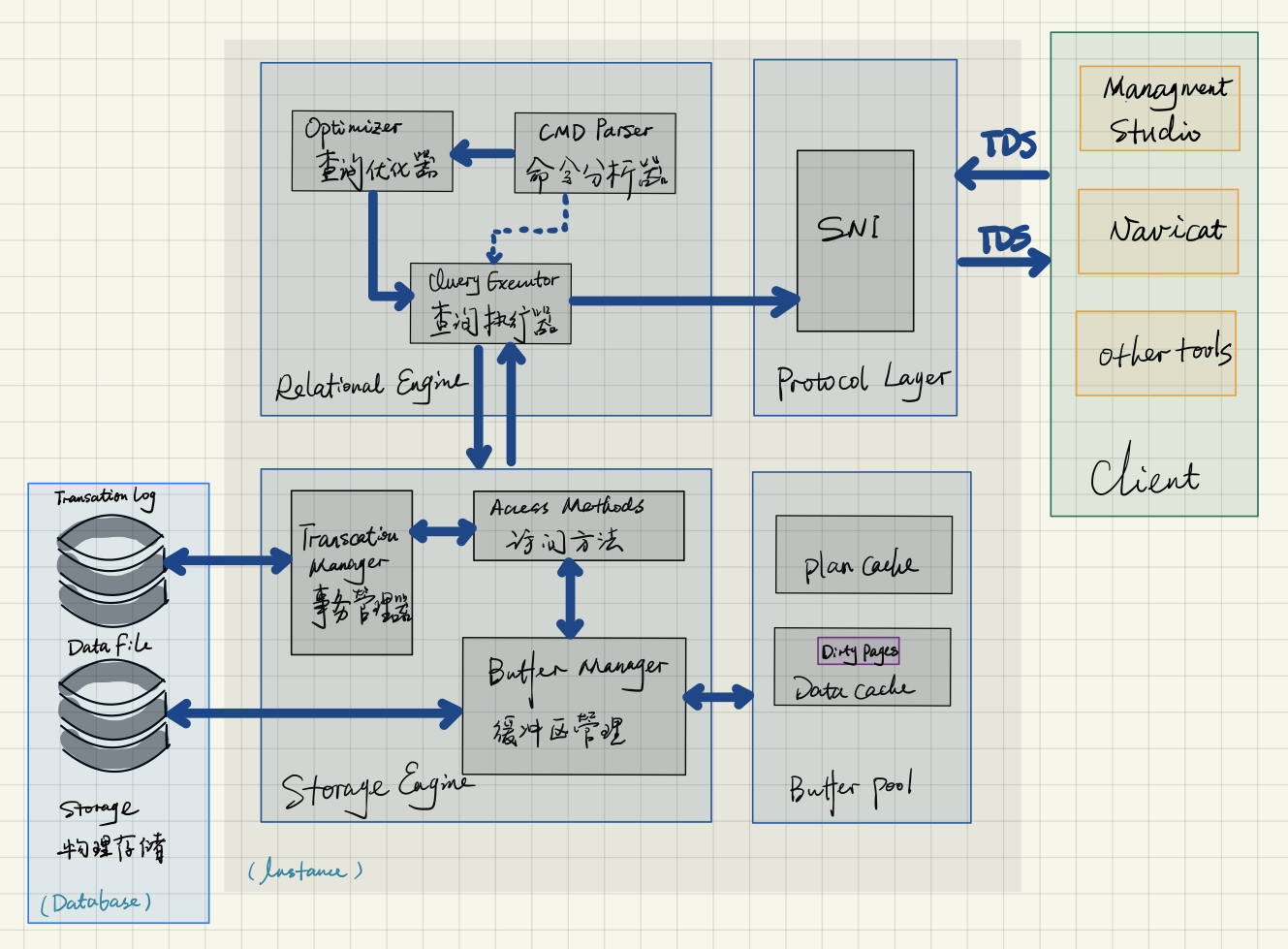
实例主要包含以下三个组件:
- 协议层(Protocol Layer):主要负责客户端的连接请求和数据通信;
- 关系引擎(Relational Engine):主要负责 SQL 语句的解析、优化和执行;
- 存储引擎(Storage Engine):主要负责数据和日志的存储和访问、内存和缓存管理、事务和锁管理。
SQL Server客户端访问工具
SQL Server客户端访问工具,提供了远程访问技术,它与SQL Server服务端基于一定的协议,使其能够远程访问数据库,就像在本地操作数据库一样,如我们经常用的Microsoft SQL Server Management Studio。
SQL Server客户端访问工具是比较多的,其中比较流行的要数Microsoft SQL Server Management Studio 和Navicat(Navicat在MySQL中也是比较常用的)
SQL Server网络协议
SQL Server网络协议,又叫SQL Server网络接口(SNI),它是构成客户端和服务端通信的桥梁,它与SQL Server服务端基于一定协议,方可通信。
SQL Server网络协议,由一组API构成,这些API供SQL Server数据库引擎和SQL Server本地客户端调用,如实现最基本的CRUD通信。
SQL Server 网络接口(SQL Server Network Interface,SNI)只需要在客户端和服务端配置网络协议即可,它支持以下协议:
(1)共享内存-Shared Memory
(2)TCP/IP
(3)命名管道-Named Pipes
共享内存协议
当客户端应用和 Microsoft SQL Server 服务位于同一台机器时,可以使用共享内存协议进行通信。
使用 SSMS 连接本地数据库时的配置Server name 选项可以设置为以下内容之一:
- .
- localhost
- 127.0.0.1
- computer name\instance name
TCP/IP 协议
TCP/IP 是远程客户端连接 Microsoft SQL Server 服务器默认使用的方式。
在 SSMS 工具中通过 TCP/IP 连接数据库的配置服务器的地址和端口;Microsoft SQL Server 默认监听的 TCP/IP 端口为 1433。
命名管道协议
命名管道是一种实现进程间通信的 FIFO 机制,两个进程可以通过管道的名字打开、读写管道。如果客户端应用和 Microsoft SQL Server 服务位于同一局域网内或者同一台机器时,可以使用命名管道协议进行通信。
在 SSMS 工具中通过命名管道连接数据库的配置为
\\<server_name>\pipe\sql\<pipeline_name>
默认情况下 Microsoft SQL Server 服务器没有启用命名管道协议,可以通过 SQL Server Configuration Manager 工具进行配置。对于本地数据库,默认创建的命名管道为
\\.\pipe\sql\query
TDS 协议
客户端连接建立后,可以发送查询语句给服务器,服务器执行完成之后再将结果返回给客户端。Microsoft SQL Server 在应用层使用 TDS( Tabular Data Stream、表格数据流)协议实现客户端和服务器之间的数据传输请求和响应。
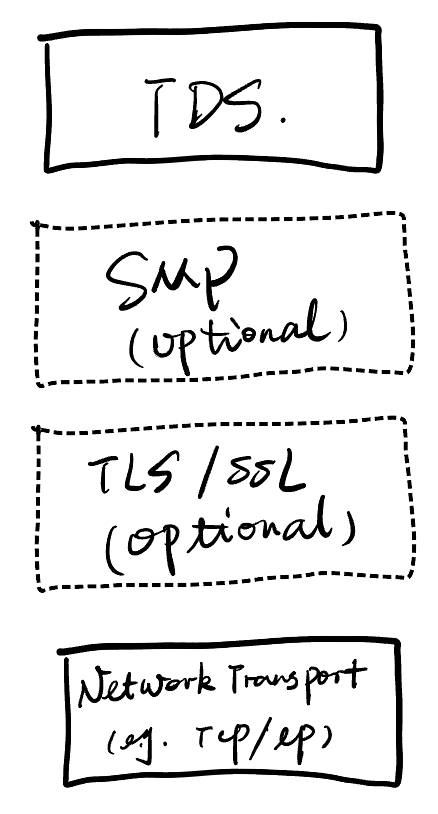
TDS 会话直接与底层的传输级会话绑定,意味着在建立传输级连接之后,服务器接收到建立 TDS 连接的请求时建立 TDS 会话。TDS 会话一直持续到传输级连接终止(例如关闭 TCP 套接字时)。
TDS 包含了用于身份验证和标识、通道加密协商、SQL 批处理命令提交、存储过程调用、数据返回以及事务管理器请求等功能。返回的数据具有自描述性并且是面向记录的。
数据流包含了要返回的数据行名称、类型以及可选的描述。
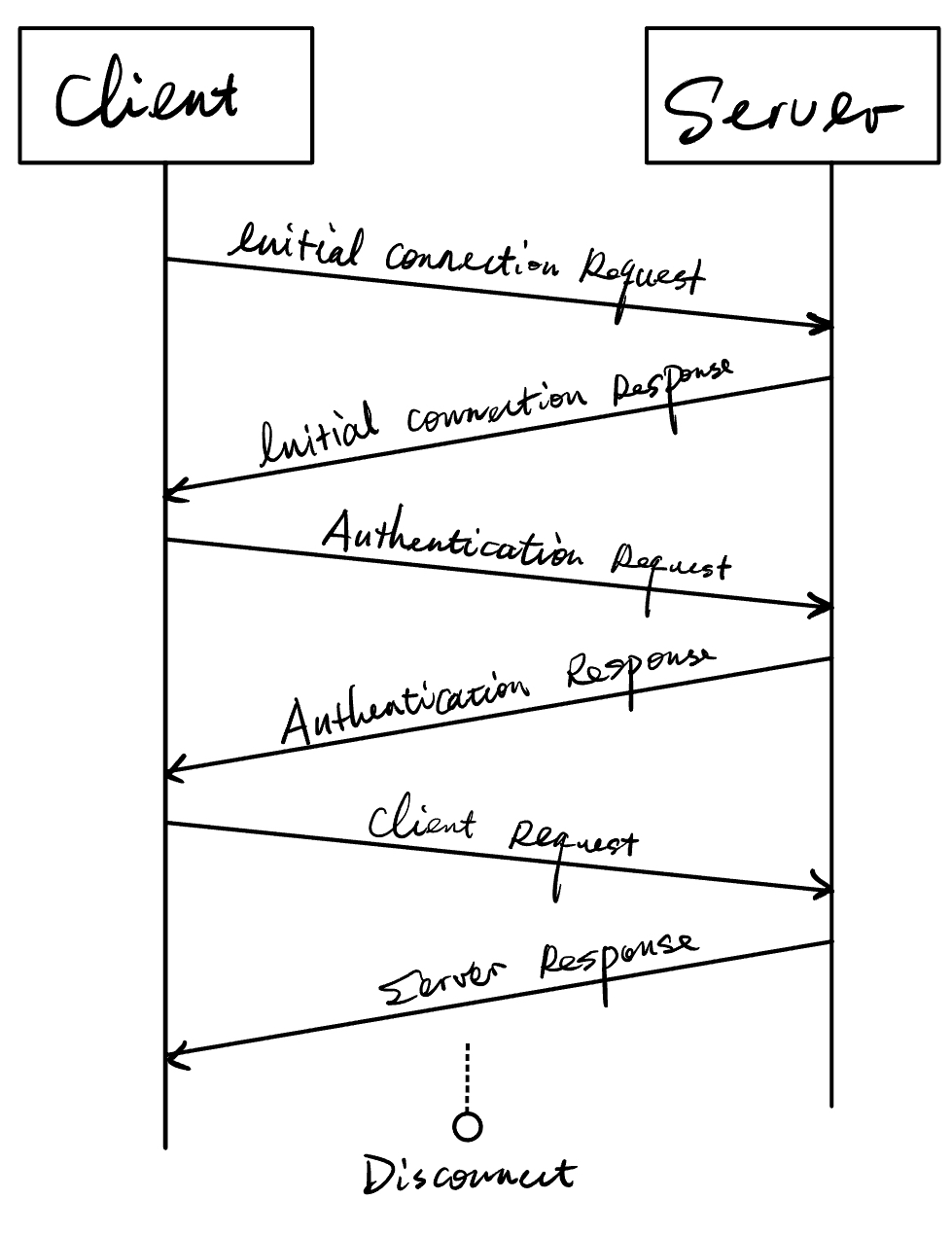
下图描绘了 TDS 协议中一个典型的(简化的)通信流程:
关系引擎
Microsoft SQL Server 协议层接收到客户端的请求并处理之后,将语句传递给关系引擎进行处理。关系引擎也被称为查询处理器(Query Processor)。关系引擎决定了查询需要执行的操作以及如何最好地实现该操作,负责请求存储引擎获取用户所需的数据并且对结果进行处理,然后通过协议层将结果返回给客户端。
关系引擎包含了以下三个主要部分:
- 命令解析器(CMD Parser);
- 查询优化器(Query Optimizer);
- 查询执行器(Query Executor)。
命令解析器
命令解析器主要的作用是检查 T-SQL 语句的语法和语义错误,并创建一个内部的查询树(Query Tree)。
Microsoft SQL Server 和其他编程语言一样预定义了很多关键字,同时具有自己的语法格式。例如,SELECT、INSERT、UPDATE、CREATE、DROP 等都属于预定义的关键字。命令解析器首先对输入的语句进行语法检查,如果违反了语法规则,将会返回一个错误。
完成检查之后,命令解析器为 T-SQL 语句创建一个查询树,然后传递给查询优化器。
查询优化器
查询优化器的作用是创建一个执行计划,也就是执行查询语句的具体操作。
需要注意的是,并非所有的查询都会进行优化。
DML 命令(例如 SELECT、INSERT、DELETE 以及 UPDATE 等)会发送给优化器;
DDL 命令(例如 CREATE、ALTER 等)不会进行优化,而是直接编译成内部格式。
查询优化器的输入包括查询语句、数据库模式(表和索引的定义)以及数据库统计信息。 查询优化器的输出称为“查询执行计划”,有时也称为“查询计划”或为“执行计划”。
在优化单个 SELECT 语句期间查询优化器的输入和输出如下图中所示:
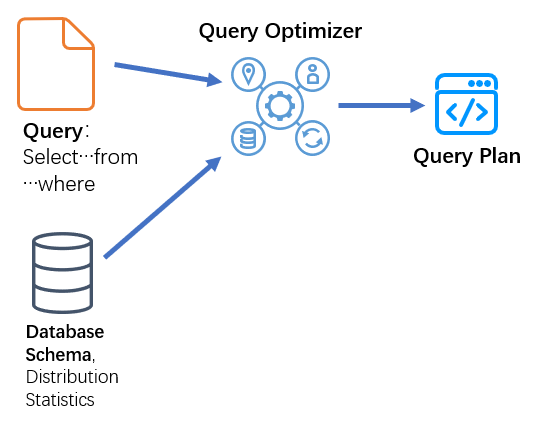
Microsoft SQL Server 查询优化器是基于成本的优化器,基于输入参数和各种因素,例如所需的 CPU 使用率、内存以及 I/O 等,对查询成本进行计算,然后找出最佳(而不是成本最低)的执行计划。
执行计划包含了从每个表提取数据的方法(表扫描或者索引访问)、多个表的访问顺序、执行计算的方法以及对每个表中的数据进行筛选、聚合和排序的方法。
查询执行器
查询执行器负责调用存储引擎执行具体的计划。存储引擎提供了获取数据的访问方法(Access Method),查询执行器将存储引擎返回的数据处理成为结果集定义的格式后,通过协议层将结果集返回客户端。
存储引擎
存储引擎负责存储系统(例如磁盘或者 SAN)中的数据存储和检索。存储引擎包含了 3 个组件:
- 访问方法(Access Method);
- 缓冲管理器(Buffer Manager);
- 事务管理器(Transaction Manager)。
访问方法
访问方法是查询执行器和缓冲管理器/事务日志之间的一个接口。
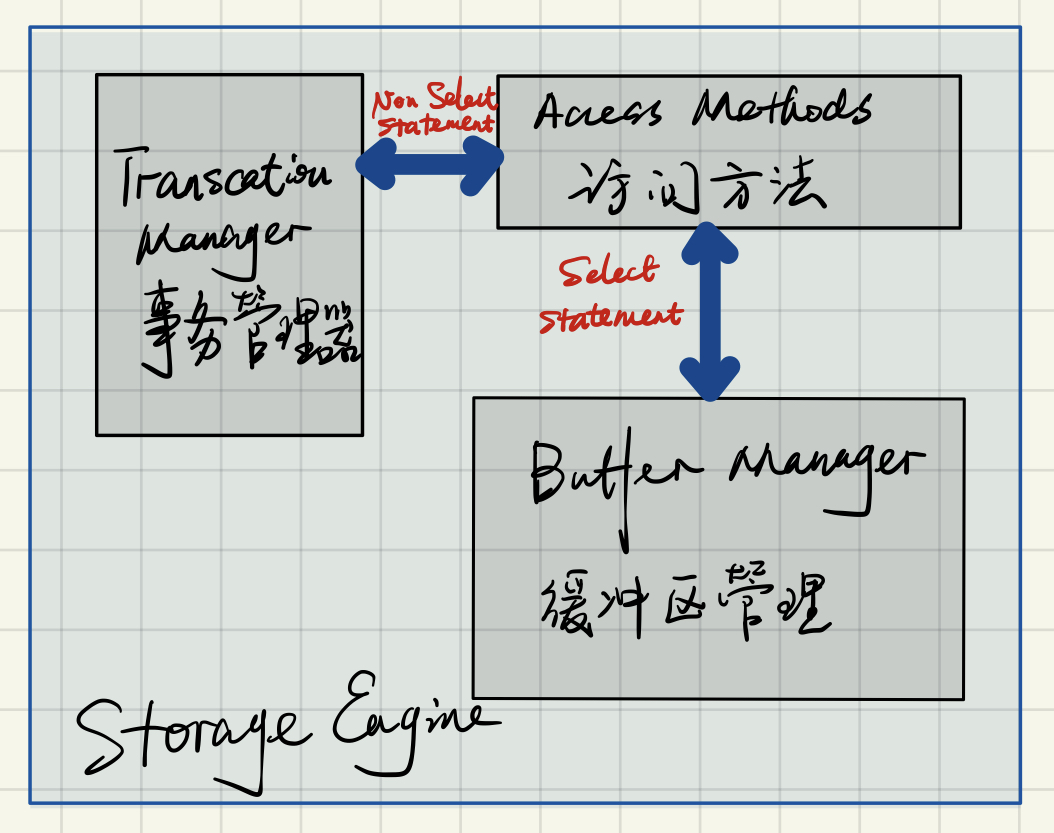
- 首先,它会判断查询的类型是 SELECT 语句还是 DDL/DML 语句;
- 如果是 SELECT 语句,则将其传递给缓冲管理器进行处理;
- 如果是 DDL 或者 DML 语句(例如 UPDATE),则将其传递给事务管理器进行处理。
缓冲管理器
缓冲管理器实现了以下核心功能模块:
- 执行计划缓存(Plan Cache);
- 数据解析(Data Parsing):缓冲区缓存(Buffer cache)和数据存储(Data storage);
- 脏页(Dirty Page):脏页是指内存中被修改过但还没有写入磁盘的数据,它由事务管理器产生。
第一次生成查询计划时,如果计划比较复杂,缓冲管理器会将该查询和相应的执行计划存储到缓存中。缓存管理器对每次查询进行检查,如果服务器接收到相同的查询,可以重用缓存的查询计划和数据。
缓存管理器还提供了数据的访问操作:
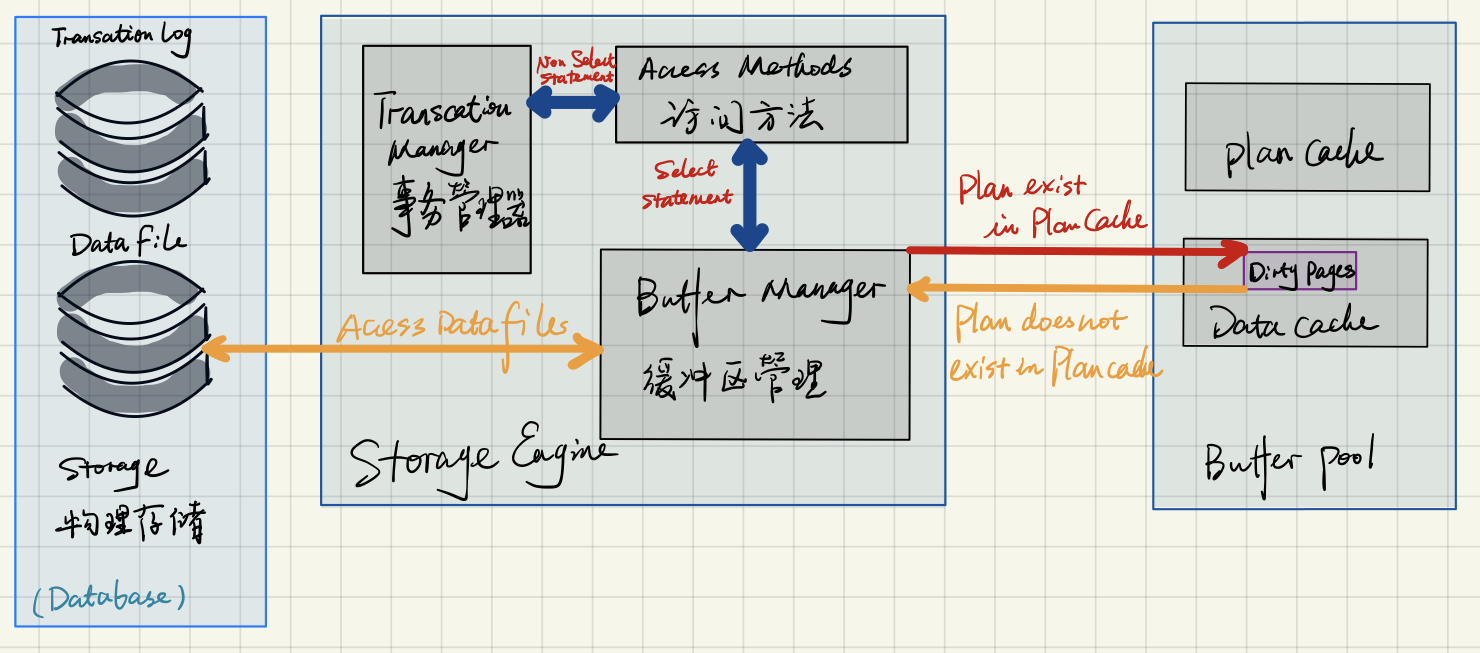
- 如果数据已经位于数据缓存(Data cache)中,直接通过缓存返回数据;这种方式减少了磁盘 I/O,提高了数据访问的性能,被称为数据的软解析(Soft Parsing)。
- 如果所需的数据不在数据缓存中,通过磁盘 I/O 访问数据存储设备中的文件,同时将数据存储到缓存中,这种方式被称为数据的硬解析(Hard Parsing)。
下面列出了一些访问方法类型:
- 行和索引操作(Row and Index Operations):负责操作和维护磁盘上的数据结构,也就是数据行和 B 树索引。
- 页分配操作(Page Allocation Operations):每个数据库都是 8KB 磁盘页的集合,这些磁盘页分布在多个物理文件中。SQL Server 使用 13 种磁盘页面结构,包括数据页面、索引页面等。
- 版本操作(Versioning Operations):用于维护行变化的版本,以支持快照隔离(Snapshot Isolation)功能等。
访问方法并不直接检索页面,它向缓冲区管理器(Buffer Manager)发送请求,缓冲区管理器在其管理的缓存中扫描页面,或者将页面从磁盘读取到缓存中。在扫描启动时,会使用预测先行(Look-ahead Mechanism)机制对页面中的行或索引进行验证。
事务管理器
**事务服务(Transaction Services)**用于提供事务的 ACID 属性支持。ACID 属性包括:
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
如果查询属于修改对象或者数据的语句,需要调用事务管理器。
事务管理器包括日志管理器(Log Manager)和锁管理器(Lock Manager)。
- 日志管理器利用事务日志(Transaction Log)中的日志项记录了系统的所有更新操作,每条日志记录由一个日志序列号(LSN)标识,同时包含了事务 ID 和数据修改记录。 Microsoft SQL Server 使用预写日志 (Write-ahead Logging) ,可以确保在将相关日志记录写入磁盘后再将数据修改写入磁盘,维护了事务的 ACID 属性。如果系统出现故障,则可能需要使用事务日志将数据库恢复到一致状态。 但写入数据页可以是异步的,所以可以在缓存中组织需要写入的数据页进行批量写入,以提高写入性能。
- 锁管理器用于在事务处理期间管理事务对所依赖的资源(如行、页或表)上请求的锁。 锁可以阻止其他事务以某种可能会导致事务请求锁出错的方式修改资源,实现事务的隔离性和一致性。
数据库事务的处理流程如下:
- 日志管理器开始记录日志,同时锁定管理器锁定相关的数据。
- 在缓冲区缓存中维护数据的副本;
- 在日志缓冲区中记录被修改数据的前后镜像,并且更新数据缓冲区中的数据副本,此时也就产生了数据的脏页;
- 检查点线程(Checkpoint)定期将数据脏页和缓冲日志写入磁盘。 SQL Server 通过 Lazy Writer 线程使用 LRU(Least recently Used)算法将数据脏页刷新到磁盘文件。
SQL Server 支持两种并发模型来保证事务的 ACID 属性:
- 悲观并发(Pessimistic Concurrency)假设冲突始终会发生,通过锁定数据来确保正确性和并发性。
- 乐观并发(Optimistic Concurrency)假设不会发生冲突,在碰到冲突再进行处理。
在乐观并发模型中,用户读数据时不锁定数据。在执行更新时,系统进行检查,查看另一个用户读过数据后是否更改了数据。如果另一个用户更改了数据,则产生一个错误,接收错误信息的用户将回滚事务。该模型主要用在数据争夺少的环境中,以及锁定数据的成本超过回滚事务的成本时。
SQL Server 提供了 5 中隔离级别(Isolation Level),在处理多用户并发时可以支持不同的并发模型。
- Read Uncommitted:仅支持悲观并发;
- Repeatable Read:仅支持悲观并发;
- Serializable:仅支持悲观并发;
- Snapshot: 支持乐观并发;
- Read Committed:默认隔离级别,依据配置既可支持悲观并发也可支持乐观并发。
另外,Microsoft SQL Server 还提供了基于行版本控制的隔离,数据库引擎将会维护修改的每一行的版本。
应用程序可以指定事务使用行版本查看事务或查询开始时存在的数据,而不是使用锁保护所有读取。 通过使用行版本控制,读取操作阻止其他事务的可能性将大大降低。
数据库文件
每个 SQL Server 数据库至少具有两个操作系统文件:一个数据文件和一个日志文件。
- 数据文件包含数据和对象,例如表、索引、存储过程和视图。
- 日志文件包含恢复数据库中的所有事务所需的信息。 为了便于分配和管理,可以将数据文件集合起来,放到文件组中。
SQL Server 数据库具有三种类型的文件:
- 主要数据文件(Primary file),包含数据库的启动信息,并指向数据库中的其他文件。 每个数据库有一个主要数据文件。 主要数据文件的建议文件扩展名是 .mdf。
- 辅助数据文件(Secondary file),用户定义的可选数据文件。 通过将每个文件放在不同的磁盘驱动器上,可将数据分散到多个磁盘中。次要数据文件的建议文件扩展名是.ndf。
- 事务日志文件(Log file),此日志包含用于恢复数据库的信息。 每个数据库必须至少有一个日志文件。 事务日志的建议文件扩展名是.ldf。
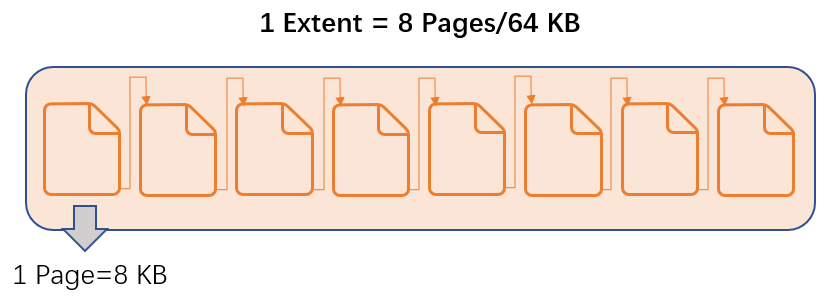
数据文件是存储数据的物理文件,由多个数据页(data page)组成; 数据页是磁盘 I/O 操作的基本单位,每个数据页大小为 8KB,是 Microsoft SQL Server 中最小的存储单元。8 个物理上连续的数据页组成一个区(extent),区是管理空间的基本单位。
每页的开头是 96 字节的标头(Page Header),用于存储有关页的系统信息,包括页码(Page Number)、页类型(Page Type)、页的可用空间以及拥有该页的对象的分配单元 ID、指向下一页和上一页的指针等。
日志文件不包含页,而是包含一系列日志记录。
默认情况下,数据和事务日志放在单磁盘系统的同一驱动器和路径上。
对于生产环境, 建议将数据和日志文件放在不同的磁盘上。